




























На этой неделе китайская компания Tencent представила новую ИИ-модель с открытым исходным кодом HunyuanWorld-Voyager. С её помощью можно генерировать 3D-видеоряд из одного исходного изображения, управляя траекторией камеры для «изучения» виртуальных сцен. Алгоритм одновременно генерирует видео в формате RGB и информацию о глубине (RGB-D), что позволяет осуществлять 3D-реконструкцию без использования традиционных методов моделирования.

Обзор ноутбука HONOR MagicBook Pro 16 HUNTER 2025. Для игр? Для работы? Для игр и работы! 
Шестиядерники за 10 тысяч рублей — сравнение и тесты 
Обзор смартфона HUAWEI Pura 80 Pro: разумный флагман с мощнейшей камерой 
Обзор планшета HUAWEI MatePad 11,5» (2025): апгрейд без бликов 
Ноутбуки HONOR MagicBook: технологии, дизайн и производительность для любых задач 
Компьютер месяца — сентябрь 2025 года 
Обзор видеокарты Acer Nitro Intel Arc B580 OC 
В чем уникальность зум-камеры HUAWEI Pura 80 Ultra? 
Источник изображений: Tencent
На самом деле результаты работы HunyuanWorld-Voyager не являются настоящими 3D-моделями, но создаётся аналогичный эффект. ИИ-алгоритм генерирует 2D-видеокадры, которые сохраняют пространственную согласованность, как если бы камера перемещалась в реальном 3D-пространстве. В каждой генерации создаётся всего 49 кадров, т.е. примерно две секунды видео. По данным Tencent, несколько клипов могут быть объединены в последовательности продолжительностью «несколько минут». Объекты сохраняют своё положение, когда камера перемещается вокруг них, перспектива изменяется корректно, как если бы это происходило в реальной 3D-среде. Хотя результатом работы является видео с картами глубины, а не полноценные 3D-модели, эти данные можно преобразовывать в 3D-облака точек для дальнейшей реконструкции.
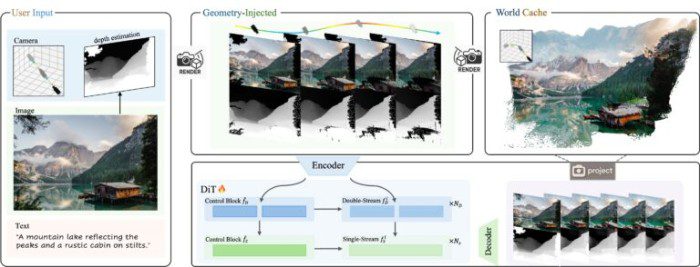
Система работает на основе одного исходного изображения и заданной пользователем траектории камеры. Можно задать движение камеры вперёд, назад, влево, вправо или поворот, для чего предусмотрен интерфейс управления. Система объединяет данные об изображении и глубине с другими данными для формирования видеоряда, отражающего движение камеры, которое задал пользователь.
Основным ограничением всех ИИ-моделей на базе архитектуры Transformer является то, что они в основном имитируют паттерны, найденные в данных для обучения, что ограничивает их возможности в плане «обобщения», т.е. применения этих шаблонов в новых ситуациях, которые не встречались при обучении. Для обучения HunyuanWorld-Voyager исследователи задействовали более 100 тыс. видеоклипов, включая компьютерные сцены на движке Unreal Engine. По сути они обучали ИИ-алгоритм имитировать движение 3D-камер в среде видеоигр.
Большинство ИИ-генераторов, таких как Sora, создают выглядящие правдоподобно кадры друг за другом, не пытаясь отслеживать или поддерживать пространственную согласованность. В отличие от этого HunyuanWorld-Voyager обучен распознавать и воспроизводить закономерности пространственной согласованности, но с добавлением обратной геометрической связи. Когда он генерирует каждый кадр, осуществляется преобразование выходных данных в точечный 3D-объект, после чего эти точки проецируются обратно в 2D для использования в будущих кадрах.
Такой подход заставляет ИИ-модель сопоставлять изученные ранее шаблоны с геометрически согласованными проекциями, полученными в процессе работы. Это обеспечивает гораздо лучшую пространственную согласованность, чем у других ИИ-генераторов видео. Однако в основе подхода всё же лежит сопоставление паттернов, основанное на геометрических ограничениях, а не полноценное «понимание» 3D. Это объясняет, почему ИИ-модель может сохранять согласованность в течение нескольких минут, но с трудом справляется с поворот сцены на 360°. Ошибки при сопоставлении с образцом накапливаются на протяжении многих кадров до тех пор, пока геометрические ограничения уже не могут поддерживать согласованность.
По данным Tencent, HunyuanWorld-Voyager использует в работе два основных блока, работающих совместно. Во-первых, система генерирует цветное видео и информацию о глубине одновременно, чтобы убедиться, что они идеально совпадают. Во-вторых, используется то, что Tencent называет «глобальным кэшем» — растущая коллекция точечных 3D-моделей, созданных из ранее сгенерированных кадров. В процессе генерации новых кадров это облако 3D-точек проецируется обратно в 2D с нового ракурса камеры для создания изображений, показывающих то, что должно быть видно на основе предыдущих кадров. Затем модель использует эти проекции для проверки согласованности, обеспечивая соответствие новых кадров уже сгенерированным.
HunyuanWorld-Voyager развивает идеи более ранней ИИ-модели Tencent HunyuanWorld 1.0, которая была выпущена в июле. Алгоритм также является частью более масштабной экосистемы Tencent Hunyuan, которая также включает в себя алгоритмы Hunyuan3D-2 для генерации 3D-объектов по текстовому описанию и HunyuanVideo для генерации видео.
Для обеспечения работоспособности HunyuanWorld-Voyager требуются значительные вычислительные мощности. Tencent рекомендует использовать не менее 60 Гбайт видеопамяти для получения 3D-сцен с разрешением 540p или 80 Гбайт видеопамяти для повышения качества картинки. Получить доступ к исходному коду ИИ-модели и сопутствующей документации можно на портале Hugging Face. Как и другие ИИ-модели семейства Hunyuan, новый алгоритм поставляется с существенными лицензионными ограничениями. К примеру, лицензия запрещает использовать HunyuanWorld-Voyager в ЕС, Великобритании и Южной Корее. Отдельного лицензирования требует коммерческое использование, предполагающее обслуживание более 100 млн пользователей в месяц.
Источник: 3Dnews.ru





